When company owns tens of routers, fiber-optic lines and advanced network within the city, there inevitably arises a necessity to formally establish the company as a provider and to provide Internet access services, including the provision of such services to third-party organizations. This is an administrative task, which includes acquisition of license, search and formation of customer database, advertising, and setting up of the Law Enforcement Support System (LESS).
It goes without saying that from technical point of view certain preparations are to be made as well. One must make an estimate for the resources, power, ports, and prepare a QoS policy. However, all of these (except for QoS) are a routine.
We want to discuss something else – IBGP. One may find this topic a bit far-fetched, because many consider internal BGP to be the prerogative of rather large providers. However, it is not the case. Currently, enterprises use iBGP even more often than providers do, for the sole purpose of internal routing. For example, for VPN – a very popular application, based on BGP in the corporate environment. Another example is a highly valuable option of organizing the L3 isolated areas within the infrastructure that has already been built. There may be about fifty or even ten prefixes – no Full View, but still very handy.
So let us assume that the network is already quite big, and there is a need in BGP core.
In this article we will discuss
- When IBGP is needed
- How it is different from the EBGP
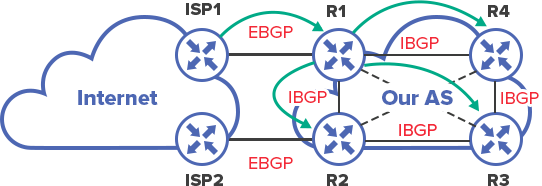
What is IBGP
Let us start with the notion of Internal BGP. Essentially it is the same BGP, but inside the AS. It is even configured in a similar way.
There are two main applications:
Redundancy. When there are several connections to providers and one ties to avoid linking everything to one edge router (the so-called border), several routers are put in place and IBGP is established between them, so that they always have up-to-date information about all routes.
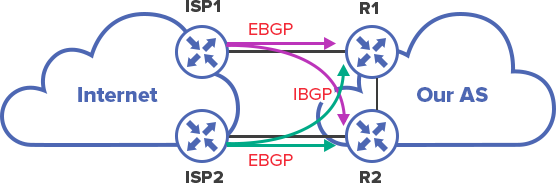
| ➞ | routing information |
| ➞ |
In case ISP2 experiences issues, R2 will know that the same network is available through ISP1. R1 will inform R2 about it through IBGP.
Connecting customers through BGP. If the goal is to connect client by BGP, and there are several routers, this cannot be accomplished without IBGP.
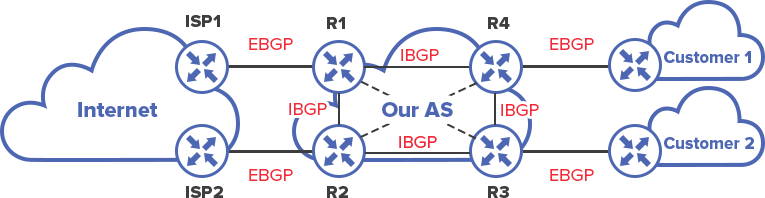
In order to send Full View to “Customer 1”, R4 has to obtain it through IBGP from R1 or R2.
EBGP is used between Autonomous Systems, IBGP – inside the AS.
The differences between IBGP and EBGP
1. The main subtlety, that appears when you move into the autonomous system, where almost all differences take their roots are loops. EBGP allows coping with them through the AS-Path. If the list already contains its own AS number, then this route is discarded.
However, in the propagation of route within an autonomous system AS-Path is not changed. IBGP resort to trickery instead – using full mesh topology, where all the neighbors have a session with everyone – Full Mesh.
Thus, a route received from IBGP neighbor is not advertised to other IBGP-neighbors.
This allows all routers to have all routes and thus avoid loops.
Here is an example:
How it might have been in such a topology, if for example, the technology of avoiding loops was not used:
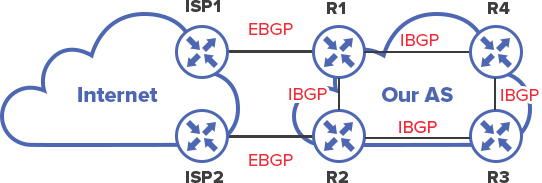
R1 received the announcement from the EBGP neighbor, announced it to R2, which in its turn sent it to R3, R3 sent it to R4. At first glance looks like everything is fine, everyone knows where the Internet is. Nevertheless, R4 transmits the announcement back to R1.
R1 received the route from R4, and it is as preferable as the original update from the ISP, AS-Path has not changed. Therefore, the new route from the R4 may receive higher priority, which is, obviously an unwanted priority shift: in addition to the fact that the routes will be wrongly learned, the traffic can eventually go into loop and will not reach the destination.
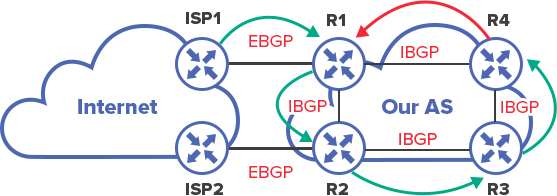
➞ routing information
➞ traffic route
In case of a full mesh topology and Split Horizon rule, possibility of such situation is eliminated. R1 receives the announcement from ISP1, sends it directly to all its neighbors: R2, R3, R4. Neighbors, in their turn, keep these announcements, but send them only to EBGP partners, not IBGP, namely because they are obtained from IBGP partner. In other words, all BGP routers have up to date information and the possibility of loops is eliminated.
➞ routing information
Moreover, it does not matter whether the neighbors are connected directly or through intermediate routers. For example, in the above diagram, R1 has no direct connection to R3 – they communicate through R2, but this does not prevent them from establishing TCP session and BGP on top of it.
Split Horizon concept is used here in a broader sense. If in RIP it would have meant “not to send announcements back to the interface where they came from”, in IBGP it means “not to send announcements from an IBGP partner to other IBGP partners”.
2. The second subtlety – Next Hop Address. In case of EBGP, router changes Next-Hop to its own and then sends the announcement to its EBGP neighbor. The logic is rather clear.
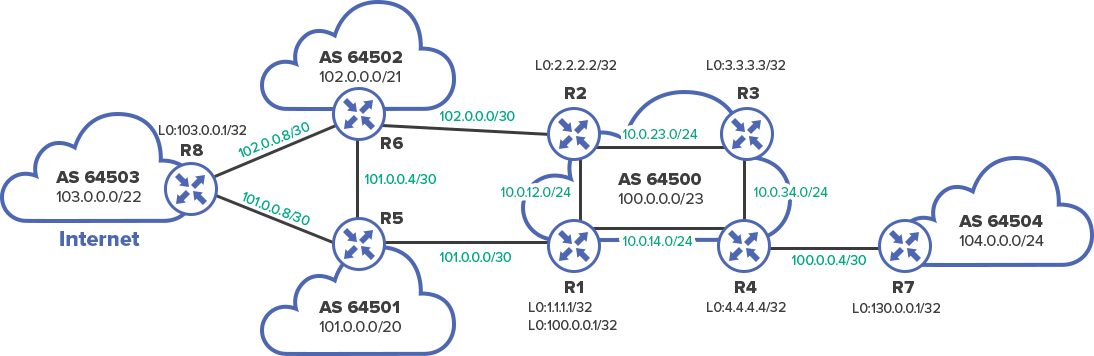
Here is how 103.0.0.0/22 network announcement looks when sending from R5 to R1:
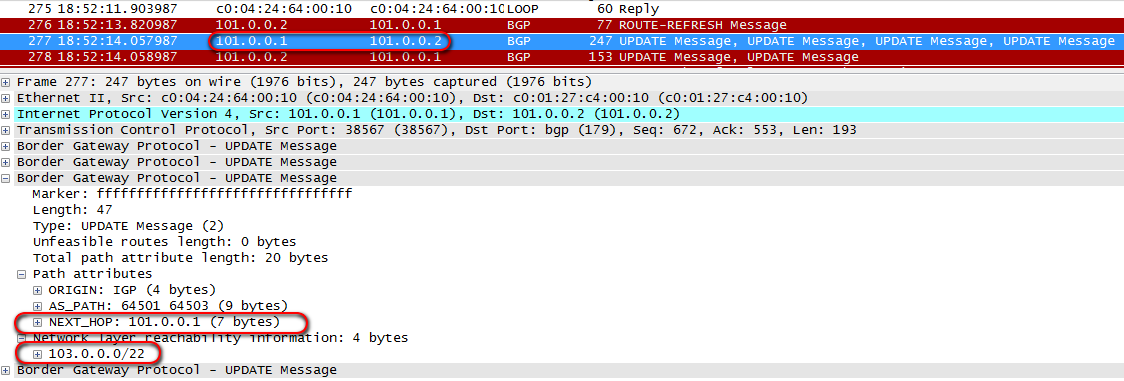
If the router sends announcement to IBGP neighbor, the address of the Next-Hop is not changed. It is unclear why. It differs from the usual understanding of the DV (Distance Vector) routing protocol.
Here is the same announcement when sending from R1 to R2:
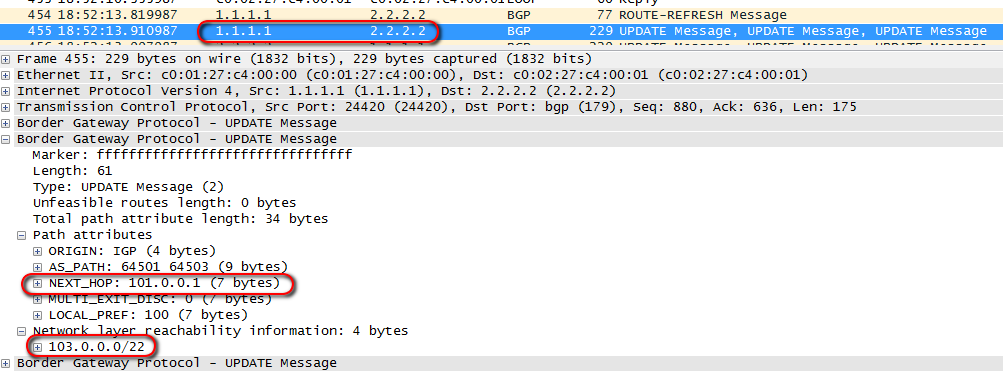
The fact is that here the concept of Next-Hop differs from one used in the IGP. In IBGP it announces the exit point from the local AS.
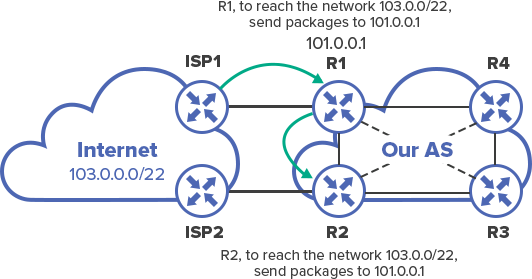
And there is one more thing – it is important for the recipient of this announcement to have the route to the Next-Hop, which is checked when selecting the best route. If it does not have it, the route is placed in the BGP table, but not in the routing table.
This process is called recursive routing.
In other words, in order to be able to send packets to ISP1, R2 must know how to reach 101.0.0.1 address, which this topology is the Next-Hop for 103.0.0.0/22 network.
In fact, almost all of the equipment allows changing the Next-Hop address in transmission of route to IBGP neighbor.
On Cisco this is done with “neighbor XYZ Next-Hop-self” command. Further on its practical application will be discussed.
3. The third point: if EBGP usually implies a direct connection between the two neighbors, the Internal BGP neighbors can be connected through multiple intermediate devices.
In fact, you can also configure EBGP neighbors that are a few hops away from each other and it is actually practiced. For example, in the case of Inter-AS Option C setting. It is called MultiHop BGP and it is enabled via “neighbor XYZ ebgp-multihop” command in the BGP configuration mode.
However, for IBGP it is running by default.
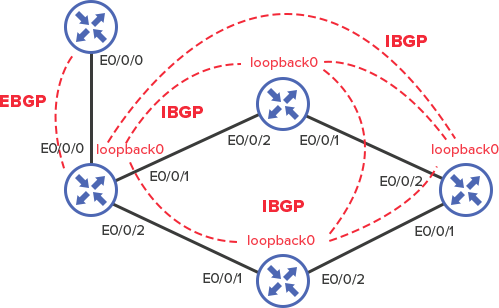
It allows setting the BGP partnership between the Loopback addresses. This is done in order not to become attached to physical interfaces – in case of the main link failure BGP-session will not be interrupted because loopback will be available through the backup.
This is the most common practice.
Nevertheless, EBGP is frequently configured on the link address, because there usually is only one connection and in case of falling, Loopback will not be available anyway. Moreover, customization of additional routing to the ISP is not very desirable.
A configuration example of such a neighbor relationship:
EBGP
Let us begin with a session configuration example with a new client:
Everything is simple and clear, after configuring all the external neighbors, one will have the following situation:
interface FastEthernet1/0 ip address 100.0.0.5 255.255.255.252 router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 100.0.0.6 remote-as 64504
interface Loopback1 ip address 130.0.0.1 255.255.255.255 ! interface FastEthernet0/0 ip address 100.0.0.6 255.255.255.252 ! router bgp 64504 network 130.0.0.0 mask 255.255.255.0 neighbor 100.0.0.5 remote-as 64500
Each BGP router knows only of those networks, which it received directly from the EBGP-neighbor.
IBGP
Let us refer to routers’ configuration in AS in terms of IBGP.
As it was previously mentioned, IBGP is usually established between Loopback interfaces for high availability, so the first step is to create them:
Loopback0 interface with the IP address X.X.X.X, where X – number of the router, must be configured on all routers (this is just an example, do not try to do this in a real network):
interface Loopback0 ip address 1.1.1.1 255.255.255.255
interface Loopback0 ip address 2.2.2.2 255.255.255.255
interface Loopback0 ip address 3.3.3.3 255.255.255.255
interface Loopback0 ip address 4.4.4.4 255.255.255.255
They will be Router ID for OSPF and BGP as well.
Speaking of OSPF. Generally, IBGP “is laid” over the existing network on the IGP. IGP provides connectivity between all routers over IP, quick reaction to topology changes and routing information exchange about internal networks.
Setting of internal routing. OSPF
The goal here is to let everyone know about subnet addresses of all links, Loopback interfaces and, of course, about white addresses.
OSPF configuration:
router ospf 1 network 1.1.1.1 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0
router ospf 1 network 2.2.2.2 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0
router ospf 1 network 3.3.3.3 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0
router ospf 1 network 4.4.4.4 0.0.0.0 area 0 network 10.0.0.0 0.255.255.255 area 0 network 100.0.0.0 0.0.1.255 area 0
After that, there appears a connection to all the Loopback addresses.
Configuring BGP
All the neighbors have to be manually configured on each node:
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0
The neighbor 2.2.2.2 remote-as 64500 kind of command declares neighbor and says that it is located in AS 64500, BGP understands that the router itself operates in the same AS, and further considers 2.2.2.2 its IBGP partner.
The neighbor 2.2.2.2 update-source Loopback0 type of command specifies that the connection will be established with the Loopback interface address. The fact is that this neighbor is set as 1.1.1.1 on the other side (on 2.2.2.2) and will be waiting all BGP messages from this address.
This type of configuration is applied to all nodes of our AS:
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 4.4.4.4 remote-as 64500 neighbor 4.4.4.4 update-source Loopback0
router bgp 64500 network 100.0.0.0 mask 255.255.254.0 neighbor 1.1.1.1 remote-as 64500 neighbor 1.1.1.1 update-source Loopback0 neighbor 2.2.2.2 remote-as 64500 neighbor 2.2.2.2 update-source Loopback0 neighbor 3.3.3.3 remote-as 64500 neighbor 3.3.3.3 update-source Loopback0
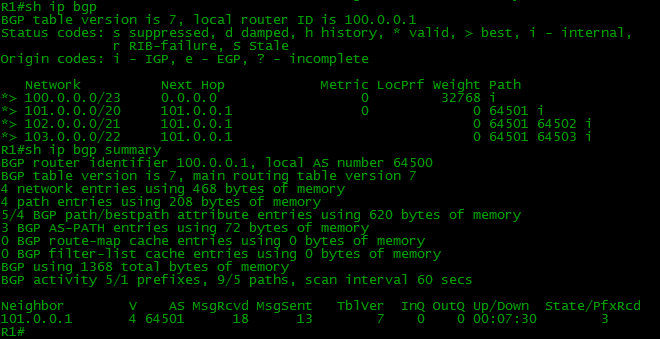
Now we can check that neighbor relationships were successfully established.
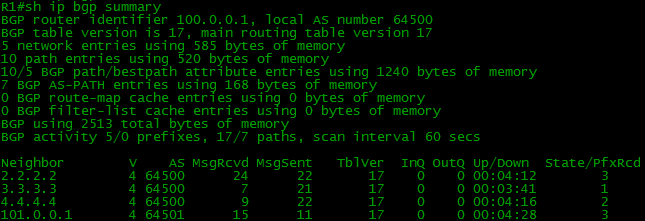
All the routes are present in our BGP table.
The 130.0.0.0/24 network is present on R1:
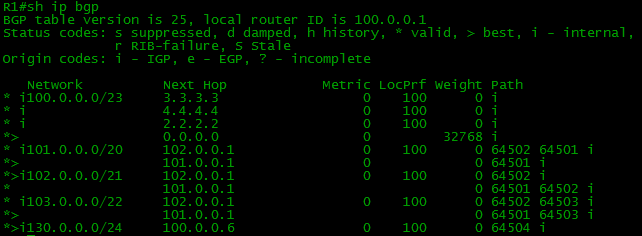
The 103.0.0.0/22 network is present on R4:
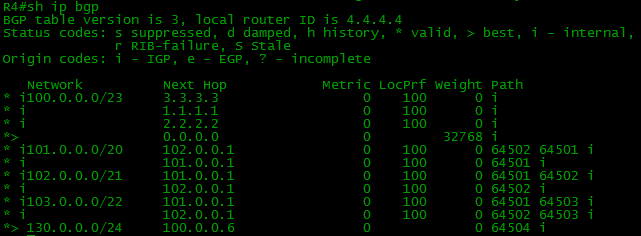
It is time to check a ping from R7 (our client) to Internet (103.0.0.1)

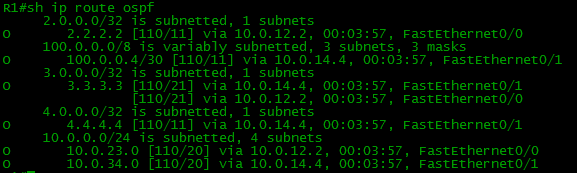
It failed. Let us look into the R4’s routing table.
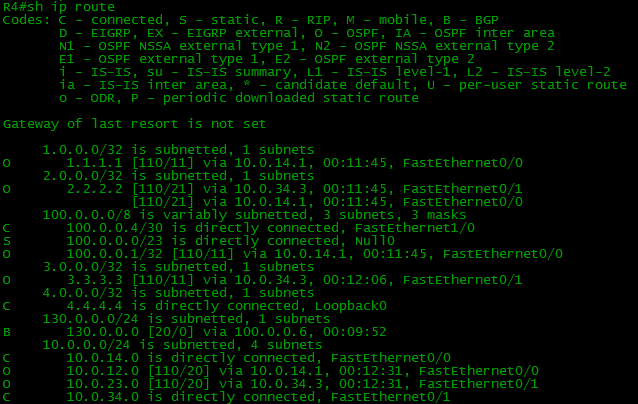
And at the same time on R7
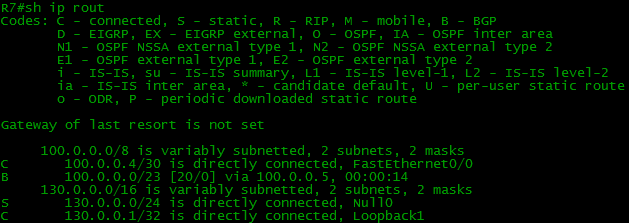
Where are the routes? R4 does not know anything about the Balagan-Telecom network, Filkina Certificate, Internet, correspondingly they are not present in R7 as well.
It was mentioned above that the Next-Hop does not change during transmission over IBGP
Note the Next-Hops of the routes received by R4:
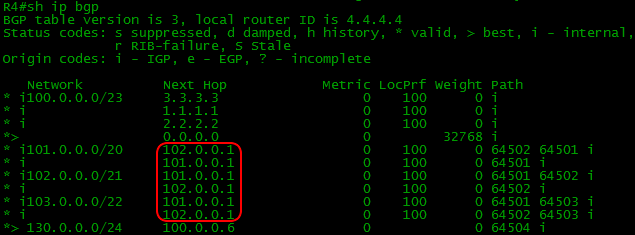
Despite the fact that they came to R4 from R1 and R2, Next-Hop addresses are R5 and R6 – i.e. they did not change.
This means that R4 must send traffic for the 103.0.0.0/22 network either to 101.0.0.1 or to 102.0.0.1. Where are they in the routing table? They are not in the routing table and cannot be there.
There exist 3 ways of solving this problem:
1) Set up static routes to these addresses – not fun at all, even if it is a gateway of last resort.
2) Add the interfaces (toward providers) in the IGP routing domain. It is also an option, but it is not recommended to add the external networks in IGP.
3) Change the Next-Hop address when sending to IBGP neighbors. Concise and easily accomplished.
As a result, we are adding one more command in BGP: neighbor 2.2.2.2 next-hop-self. For each neighbor on each node.
After that, the following situation can be seen:
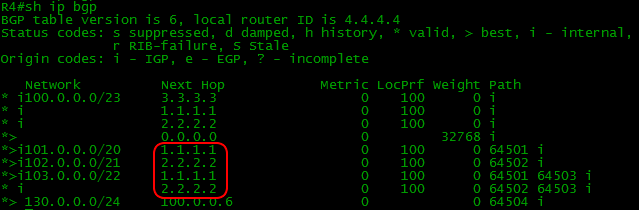
It is clear how to get to 1.1.1.1 because of OSPF:

As one can see, all the networks have appeared in the R7 table.
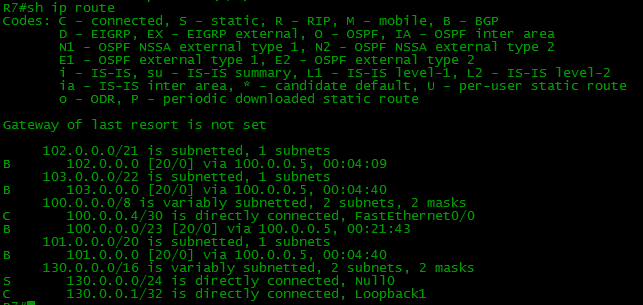
Now the ping is running successfully:

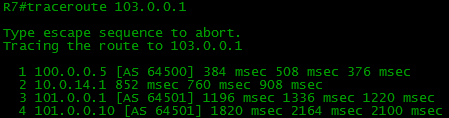
A very simple question: why there is such a considerable delay in the trace? The following situation can also be frequently observed:

What can be improved?
The BGP configuration process. It still takes an effort to make similar configuration on each node. To simplify configuration process, peer-group concept was introduced, which as the name implies, can combine neighbors into groups and set the desired parameters for all at once.
We will implement it on our network to provide a better notion:
The neighbor AS64500 peer-group command creates AS64500 group of neighbors.
The neighbor AS64500 remote-as 64500 command states that all neighbors are in AS 64500.
The neighbor AS64500 update-source Loopback0 command indicates that the connection to all the neighbors will be established with the Loopback interface address.
The neighbor AS64500 Next-Hop-self command causes the router to change the address of the Next-Hop to its own when sending announcements to all the neighbors.
Then neighbors are added to this group.
We can easily copy the neighbor group configuration commands to other routers, changing only the address of the neighbors.
A couple of comments on Peer-group:
1) Policies must be identical for all the group participants.
2) In fact, Cisco has been using dynamic Update-groups for a long time. This saves CPU resources as processing is not carried out simultaneously for each member of the group, but once for the entire group. Actually, Peer-groups only facilitate the configuration, but optimization is relegated to Update-groups.
One may wonder why the information about public addresses cannot be transmitted over IBGP? Another question is why you cannot do everything with just BGP, without for example OSPF or IS-IS? In fact, it is a routing protocol too, so what is the difference whether to transfer information between AS or between routers – there is an Internal BGP as well.
Nevertheless, experience in working with BGP on a real network shows that such venture is irrational.
The most important obstacle – Full Mesh. Neighborhood with all the all routers has to be installed manually. Despite the presence of Route Reflectors and scripts, these operations are unnecessary.
Another problem – slow reaction and distance vector approach to the propagations of routing information.
Despite the fact that there exists BFD that will reduce the detection time problem, the convergence/connectivity recovery will still be slow.
Third issue – the lack of the ability to automatically learn neighbors. It leads to the necessity of manual configuration.
All the issues described above imply scalability and maintenance problems.
To have a better notion one can simply use BGP instead of IGP on a network of 10 routers.
The same applies to the distribution of white addresses – IBGP can deal with that, but all subnets will have to be manually configured on each router.
For example, our network is 100.0.0.0/23 and R3 has three customers connected to the subnet addresses: 100.0.0.8/30, 100.0.0.12/30 and 100.0.0.16/0.
These 3 subnets will have to be inserted into BGP with three network commands, while in IGP it can be accomplished by activation of the protocol in the interface.
One can also accomplish route redistribution from IGP, but it is an irrational way and the configuration is less transparent.
So what is the bottom line? eBGP is a routing protocol. At the same time iBGP – is not quite a routing protocol. It looks more like a top-level application that arranges the distribution of routing information throughout the network in an unaltered form, without announcing each iteration to neighbor “over there through me”. Sometimes such behavior can also occur in IGP, but that is an exception there, while here it is the norm.
It should be noted that IGP and IBGP work in tandem, each doing its job.
IGP provides internal IP connectivity, fast (i.e. instantaneous) response to changes in the network, notifies all the nodes about them as quickly as possible. It is aware of the public IP addresses of our AS.
IBGP processes Internet routes in our AS and accomplishes their transit from Uplink to customers and vice versa. As a rule, it does not know anything about the structure of the internal network.
One may wonder which one “is better BGP or IS-IS?” They are fundamentally different things and cannot be compared. IBGP runs on top of IGP.
The N2problem
IBGP subject could be considered fully covered if not for the “Full Mesh”. In case of problems with a full mesh topology the solution is DR – Designated Router, which allows to reduce the number of connections between routers from n*(n-1)/2 to n-1. For IBGP this is the most common practice. Big ones have tens of BGP routers within AS. 9 neighbors need to be configured for 10 devices on each node, so it comes down to a total of at least 45 connections and 90 neighbor commands.
Thus, we approached such concepts as Route Reflector and Confederation. They will be covered in the next article.